Your 3 Minutes Guide to Bandits-Led Performance Optimization
Pixis
A lot of exciting things are happening in the world of AI. In 2017, AlphaGo – an AI-based program defeated the best human player in the game of Go. In 2019, OpenAI 5 defeated the best human DOTA2 player. Above all, autonomous driving is taking over the world.
After hearing so much, one can not be curious enough to know the magic that is making all of this possible – Reinforcement Learning.
Reinforcement learning is an AI learning method where the model is trained using a reward mechanism to promote actions that yield positive outcomes.
This type of learning is the closest approximation in trying to replicate how we learn.
We carry out tasks by taking different actions. These actions are dependent on the results of our attempts. Assessing our attempts through results, we identify the actions that helped us achieve our tasks, and avoid actions that aren’t helping.
This is how reinforcement learning works. It’s an iterative process where the model learns by itself without external guidance. Classic examples of reinforcement learning are – agent-based simulations, robotics, gaming programs, or even children.
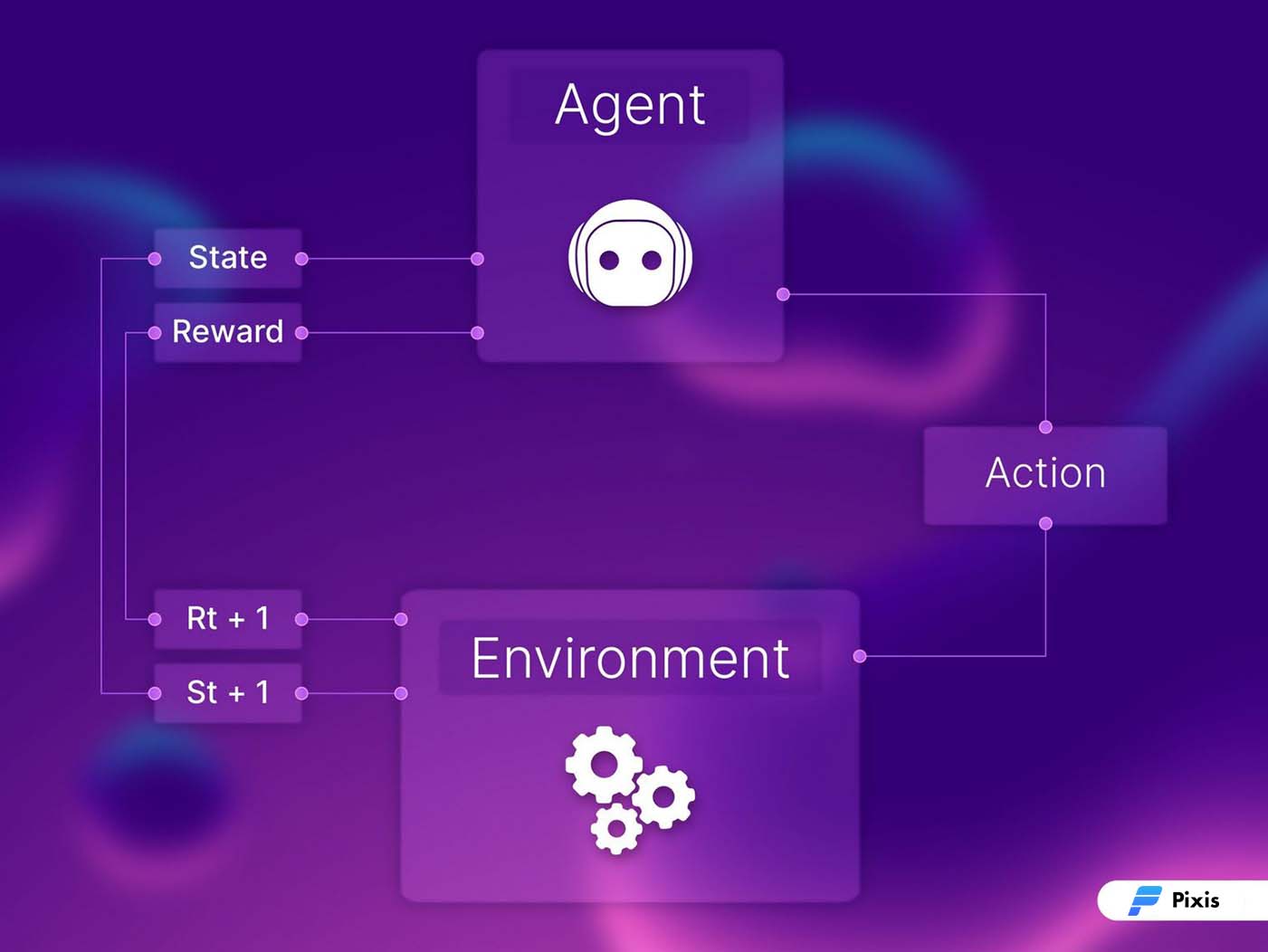
The agent here is the model or the bot. It interacts with the environment and creates new states. These states could be unlocking a new scenario or updating the structure of an existing state. Every action that the agent takes is associated with a reward metric. This metric becomes a quantifiable value to assess the model’s efficiency towards achieving a predefined goal.
If that was a lot of nerd-info, just know – if the model performs well, its confidence in that particular action increases. If it doesn’t, the confidence in that action decreases. Performing well, here means having a positive impact on the overall goal.
Multi Arm Bandits – A Classic Reinforcement Learning Example
Multi Arm Bandits is a classic reinforcement learning technique where a fixed, limited set of resources is allocated between a predetermined set of options to maximize the gain. This allocation is carried out in a stochastic fashion – the algorithm does not know which actions will result in higher gain.
It learns this through a series of exploitation phases and comes up with the most appropriate set of actions for different scenarios to maximize gain.
What is an arm?
An arm is basically an action. For example, in an email marketing campaign, an arm can be the template of the email. In a campaign performance, the arm could be budget allocation. Any action that can be taken to achieve the result can be considered as an arm.
Okay, What is multi-arms then?
A bandit is a collection of different arms. These arms are useful actions that can be performed to optimize a certain outcome. Bandit can create a mathematical model that provides a roadmap when there are multiple options available. Let’s understand how multi-arm bandits work using an example.
Suppose you are monitoring a marketing campaign and need to optimize its performance. And by the way, performance optimization is wild.
It involves crunching a lot of numbers, endless metrics monitoring, and taking a lot of actions. These actions involve changing bids & budgets for different ad sets. And they carry this strategy across hundreds of campaigns.
Ideally, marketers perform campaign optimization 2 times a day owing to extensive analysis across platforms. Campaigns that are optimized constantly throughout the running time give better results – no rocket science there.
Let’s say we are employing multi-arm bandits to optimize one of our campaigns. Multi-arms here refer to all the ad sets where the algorithm can allocate the budget to maximize ROI.
The bandit first goes through a phase of exploration. This is the phase where it learns.
Exploration Phase
Once the campaign is up and running, Bandits continuously monitor the funnel including but not restricted to CTR, LPVR, CPP, and CVR. It increases the confidence score of actions that have helped AI optimize any one of the above metrics and change actions on poor performance. This is called the exploration phase. In the framework of reinforcement learning, the AI comes to a point where it is confident about permutations of actions that can optimize the campaign.
Exploitation Phase
In the exploitation phase, the algorithm has learned the set of actions required to increase metrics like- reach percentage, frequency, impressions, CTR, link clicks, spends, LPV, CVR, and many more.
This way, bandits can continue taking those actions across all the campaigns that can maximize ROI.
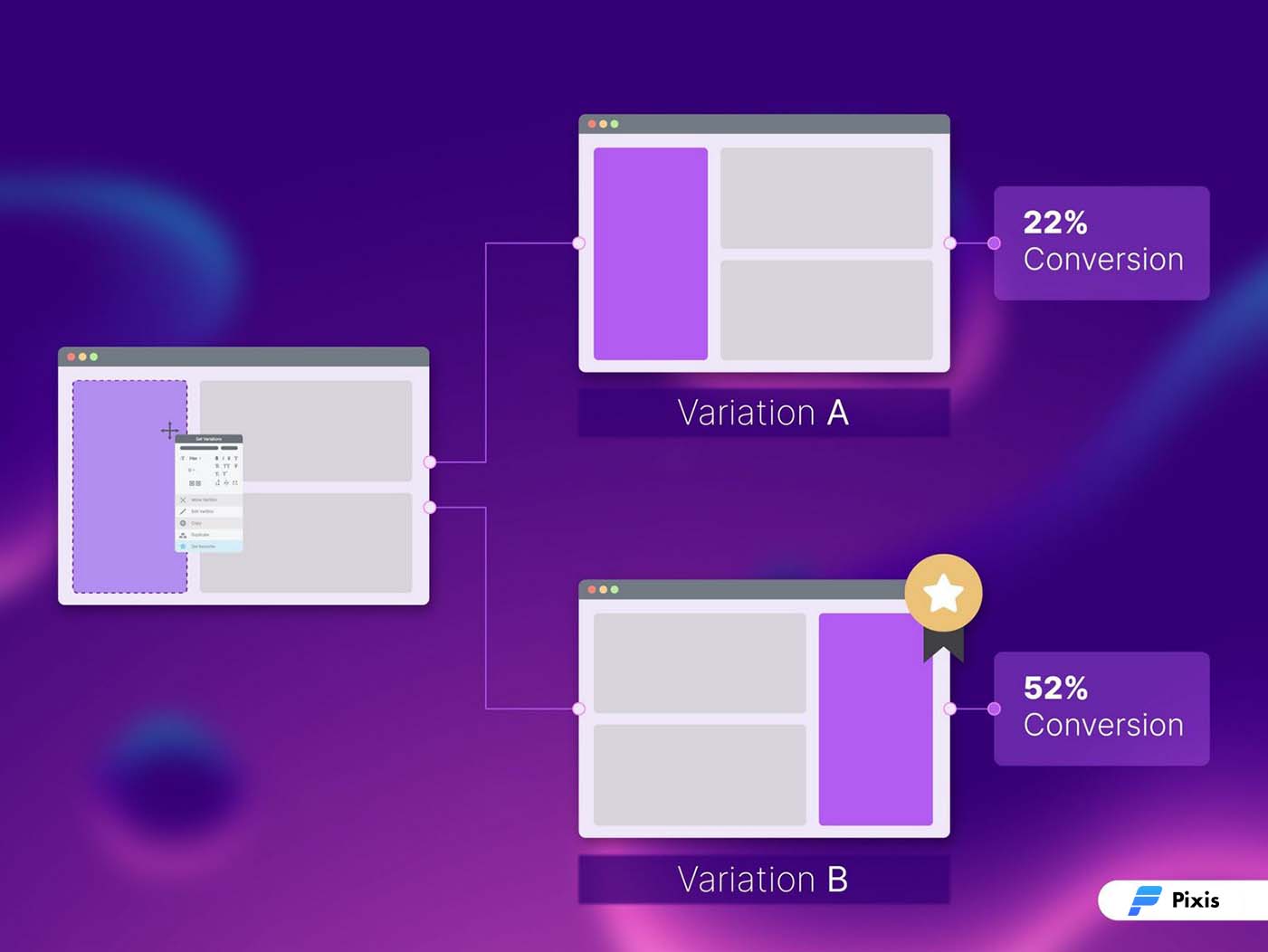
What does this mean for marketers?
Compared to traditional campaign optimization, AI-led optimization can prove to be an efficient and scalable solution to all performance management activities. It creates and continuously updates strategies around different arms such as bid and budget allocation, media planning, and creative delivery to ensure peak efficiency.
With this, marketers don’t have to invest copious amounts of time to figure out the winning arms, the bandits can find them automatically. This results in a reduction of wasteful ad spend and increases campaign efficiency.
Look, we learned how bandits work at the same time optimized our campaign! Phew!
Efficiency, Out-Of-The-Box
Today, AI has disrupted almost every industry. Increasing efficiency, scaling performances, personalizing experiences are some of the few out-of-the-box features of AI-led operations. Algorithms based on reinforcement learning such as bandits can prove to be a major factor when it comes to improving marketing efficiencies. It can be utilized to manage targeting, campaign structure, and churn effective creative recommendations at scale. All of it without your marketers breaking a sweat!




