

The franken-stack problem in marketing isn't new. We've written about it before — how disconnected tools, inconsistent data, and the absence of a shared intelligence layer quietly undermine the decisions teams think they're making with confidence. That piece focused on martech broadly. This one focuses on where the problem shows up in its most operational form: the SEO tool stack.
Every SEO tool stack audit starts by mapping the same configuration: keyword research in one platform, technical audits in another, content optimization in a third, rank tracking somewhere else, and GEO monitoring bolted on when AI search became impossible to ignore. Each subscription made sense when it was purchased. None of them were designed to hand data to the next one.
What teams end up with is not a stack. It's a collection of reporting surfaces that all require a human to sit between them and reconcile what they're saying before anything gets acted on. That reconciliation work is the franken-stack tax — and in SEO, it doesn't just slow the team down. It creates a lag between when a problem appears and when a content or technical response actually ships.
The consolidation question for SEO teams isn't about cutting subscriptions. It's the same question the broader franken-stack argument surfaces: do your tools share context, or do they each produce their own version of the truth? This piece maps the five layers an SEO pipeline needs to cover, where the redundancy and disconnection actually live, and what a connected stack — one where signals flow forward rather than terminate at export — looks like in practice. For teams extending this into AI search visibility, the GEO execution guide covers how the citation and content structure layer sits on top of this foundation.
Your SEO Tool Stack Audit Should Start With Context, Not Tool Count
The SEO franken-stack fails for the same reason the broader martech franken-stack fails: not because individual tools are broken, but because each tool operates on its own slice of data with no shared logic connecting it to the rest. The cost in SEO is specific — a ranking drop that can't be traced, a content decay that goes unactioned, a competitor displacement that compounds for weeks before anyone notices.
The pattern of accumulation is consistent across teams. A keyword research platform gets purchased first because understanding what to target is the obvious starting point. A technical crawler gets added when indexing issues surface that the research tool can't diagnose. A content optimization platform arrives when rankings plateau and the brief quality comes into question. Rank tracking gets its own subscription because the research tool's built-in tracker lacks the granularity needed for weekly triage. GEO monitoring appears when AI search starts showing up in leadership conversations about visibility.
Each addition was rational. The problem is what accumulates between them. By the time five tools are running, the team is spending more time pulling data out of different platforms than acting on it. A technical crawl surfaces a cluster of pages with degraded structured data — but the content team works out of the optimization platform and never sees it. A rank tracker flags a drop on a high-intent query cluster — but no one can connect it to the content decay flagged two weeks earlier in the crawler. The data exists in each tool. The pipeline to connect it doesn't.
This is the insight that the broader franken-stack argument reaches: fragmentation isn't primarily a tool-count problem. It's an absence of shared context. Without common definitions flowing between layers — what a content signal means to a rank signal, what a rank signal means to a GEO gap — each tool produces its own version of the truth, and humans are left doing the reconciliation before any decision can be made. As Search Engine Land's 2026 tool evaluation framework notes, the most common failure mode in SEO stacks isn't choosing the wrong tools — it's choosing tools that track visibility without connecting it to the actions that change it.
The Five Layers an SEO Pipeline Needs — and Where Each One Breaks
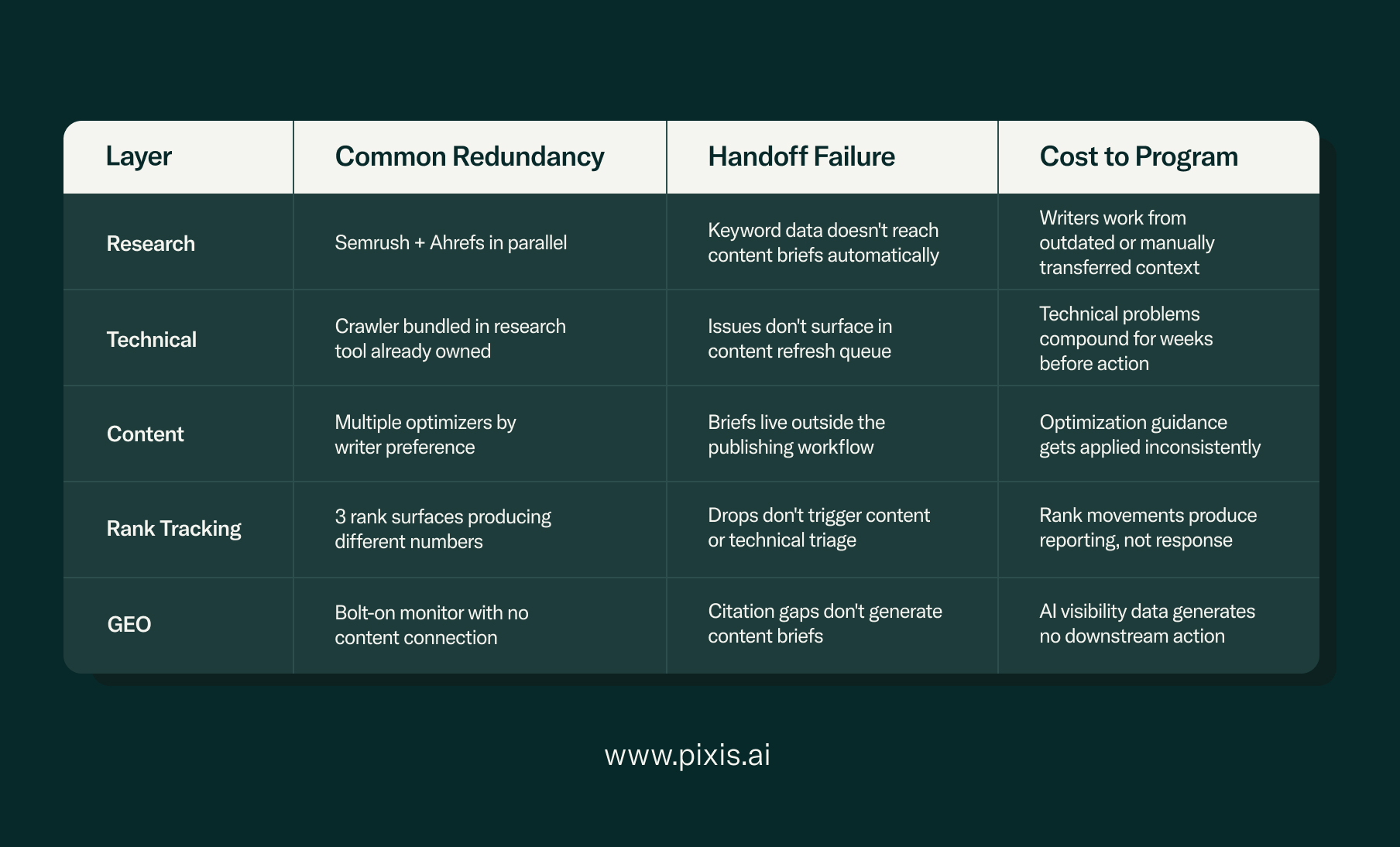
A functional SEO pipeline requires five connected layers: keyword and topic research, technical site health, content optimization, rank and performance tracking, and AI visibility (GEO). The franken-stack problem shows up differently in each layer — sometimes as redundant coverage, sometimes as a broken handoff to the next layer, sometimes as data that terminates at a dashboard rather than triggering an action.
Layer 1: Keyword and Topic Research
This is where Semrush and Ahrefs operate. Both cover keyword difficulty, search volume, competitor gap analysis, and backlink intelligence. Running both is the most common redundancy in this layer — the feature overlap for research purposes is substantial, and the typical justification ('we use Ahrefs for backlinks and Semrush for content') rarely holds up under scrutiny. The more significant handoff failure here is that keyword research data rarely flows automatically into the content briefing layer. A writer working in a separate optimization platform has no live connection to the keyword data that informed the content strategy. The gap is bridged by a human, manually, in a document.
Layer 2: Technical Site Health
Technical SEO runs on two tools that serve genuinely different functions: Screaming Frog for granular crawl data and Google Search Console for first-party indexing signals from Google directly. GSC is not optional — it's the ground truth for how Google sees the site, and it's free. Screaming Frog surfaces structural issues GSC can't reach at the URL level. The redundancy in this layer usually comes from all-in-one platforms that bundle a crawler into a subscription the team already covers elsewhere. The more consequential failure is the handoff: technical issues surfaced in the crawler rarely reach the content team as a prioritized queue. They get exported to a spreadsheet, reviewed in a monthly audit meeting, and actioned — if they're actioned — weeks later.
Layer 3: Content Optimization
This layer has the most tool duplication. Surfer SEO, Clearscope, MarketMuse, and similar platforms all analyze top-performing pages for a given query cluster and generate optimization recommendations. They serve the same core function. Teams end up with multiple subscriptions here because writers adopt tools individually, because an older contract is still running while a newer one gets onboarded, or because different sub-teams have different preferences. One is enough — provided its output connects to the briefing and publishing workflow rather than living in a separate interface that writers export from and then abandon.
Layer 4: Rank and Performance Tracking
Rank tracking is where the handoff failure is most expensive. Every research platform includes a rank tracker. Dedicated tools like AccuRanker exist as separate subscriptions. GSC provides ranking data at no cost. The result is three rank tracking surfaces producing slightly different numbers and no system logic connecting a rank movement to a specific content or technical cause. A drop that can't be traced to a cause produces anxiety but no action. The tracking layer only earns its cost when rank signals flow forward into a triage workflow — when a drop in a keyword cluster automatically surfaces a content decay flag or a technical issue that the crawler found two weeks earlier.
Layer 5: GEO and AI Visibility
This is the layer where the franken-stack problem is newest and most acute. GEO monitoring — tracking how a brand appears in ChatGPT, Perplexity, and Google AI Overviews — has been added to most stacks as a bolt-on: a separate tool, separate login, separate report. It has no connection to the content layer that would produce a response to the gaps it surfaces, and no connection to the rank layer that might explain why a piece of content has lost retrieval. The GEO dashboard problem is the franken-stack problem applied specifically to AI visibility: a monitoring layer that generates data but produces no shared context that the rest of the pipeline can act on.
Where the Stack Breaks: Layer-by-Layer Failure Mode Analysis
How to Audit Your SEO Tool Stack Before Consolidating
SEO tool stack consolidation requires answering three questions per tool: which pipeline layer does it serve, is that layer already covered, and does its output reach the next layer as an actionable input rather than a static export? Tools that fail the third question are disconnected regardless of how good their data is — and disconnected tools are what the consolidation audit exists to surface.
The audit doesn't take long. What it requires is honesty about what each tool's output actually produces — not what it could produce if someone had time to build the integration, but what it produces right now, in the current workflow.
Question 1: Which layer does this tool serve?
Map each subscription to one of the five layers. Anything that can't be assigned clearly is either a utility (project management, reporting infrastructure) or a duplicate of something already covered. Write the layer next to each tool. Anything without a clean assignment gets flagged.
Question 2: Does this layer already have coverage?
Any layer with two or more tools serving the same core function has redundancy worth examining. The question is whether the overlap is genuinely justified by a difference in use case — a crawler for daily monitoring and a separate audit tool for quarterly deep dives, for instance — or whether it's an accumulation artifact. Be specific: what does the second tool produce that the first one can't?
Question 3: Where does the data go next?
This is the consolidation question that matters more than tool count. For each tool, ask: what specific content or technical action did this tool's output produce in the last 30 days? If the answer is 'it went into a report' or 'it's available if someone needs it,' the tool is not part of a pipeline. It's a monitoring surface. Connected pipeline means the output of each layer is the input to the next — technical issues feed the content refresh queue, content decay feeds rank triage, rank triage feeds GEO gap analysis.
The franken-stack test for SEO: if answering 'why did our rankings drop for this keyword cluster last month?' requires opening four different platforms, exporting four different reports, and reconciling them manually — there is no pipeline. There is a research project that runs every time a question needs an answer.
What a Connected SEO Pipeline Actually Requires
A connected SEO pipeline is not defined by tool count — it's defined by whether signals flow forward automatically between layers. A ranking drop should surface a content decay flag. A content decay flag should surface the specific URLs that need refreshing. A GEO citation gap should generate a content brief. Each signal needs a receiver, not just a dashboard.
The connected pipeline for a mid-market B2B SEO team typically consolidates to three or four well-integrated tools: one research platform covering keyword intelligence and competitor gap analysis, GSC and Screaming Frog covering technical health with alert logic that pipes into a shared workspace, one content optimization tool whose output lives in the same system writers use for drafting, and one tracking layer whose rank movement triggers a triage workflow rather than a monthly report.
The GEO layer sits on top of this foundation and needs to operate differently from how most teams currently run it. A bolt-on monitoring tool that reports citation counts is the GEO equivalent of a rank tracker that doesn't connect to a content or technical response. The monitoring is not the problem. The absence of a shared context layer that connects what the AI is seeing to what the content team does next is.
This is the distinction between a read-only GEO layer and a read/write one. Pixis Visibility is built as the read/write execution layer for AI search: it surfaces citation gaps at the prompt-cluster level and executes the content and technical changes that close them, rather than handing a report to a human to act on separately. It applies the same principle that Prism applies to paid performance — not replacing the existing stack, but acting as the intelligence layer that makes the data between tools coherent and actionable.
The Consolidation Decision: What to Keep, What to Cut, What to Connect
Once the audit is complete, the decision follows a clear logic. Keep tools that serve a distinct pipeline layer and whose output reaches the next layer in the workflow. Cut tools that duplicate a layer already covered with no material difference in use case, or that haven't generated a specific content or technical action in the past quarter. Connect tools that serve distinct functions but currently terminate at export — this is where integration work or platform replacement earns its cost.
The financial case for consolidation is real but secondary. A typical five-tool SEO stack for a mid-market B2B team runs between $1,500 and $3,000 per month. Consolidating to three well-connected tools lands at $500–$900 for the same functional coverage. The more significant case is operational: when each layer connects to the next, the time spent reconciling conflicting data drops, and the time between a problem appearing and a response shipping shortens.
The franken-stack persisted in marketing broadly because humans filled the gaps between disconnected tools. In SEO specifically, those gaps show up as ranking drops that go undiagnosed, technical issues that don't reach the content team, and GEO citation losses that compound before anyone builds a response. SEO tool stack consolidation done well doesn't produce a smaller set of subscriptions — it produces a pipeline where the signal from one layer becomes the input to the next, and the team's time goes into the response, not the reconciliation.
FAQs
What is an SEO tool stack audit?
SEO tool stack consolidation is the process of auditing a fragmented collection of SEO tools, eliminating redundant subscriptions, and building a pipeline where each layer — research, technical health, content optimization, rank tracking, and GEO visibility — passes data forward to the next layer as an actionable input. The goal is not a smaller tool count for budget reasons alone, but a connected workflow where visibility signals produce specific content and technical responses rather than static reports that require manual reconciliation.
How many SEO tools does a B2B marketing team actually need?
A functional B2B SEO pipeline typically requires three to four tools covering distinct layers: one research platform, Google Search Console paired with a technical crawler, one content optimization tool integrated into the writing workflow, and a rank tracker with alert logic. GEO visibility adds a fifth layer — but only generates value when it connects to content execution rather than running as a standalone monitoring tool. The number is less important than whether each tool's output reaches the next layer in the pipeline.
How do I know if my SEO tools are part of a pipeline or just a collection?
The diagnostic is simple: for each tool in your current stack, ask what specific content or technical action its output produced in the last 30 days. If the answer is a report that got reviewed, or data that's available if someone needs it, the tool is a monitoring surface — not a pipeline participant. A connected pipeline means the output of each layer is the input to the next without a human manually bridging the gap. If a ranking drop requires opening four platforms to diagnose, there is no pipeline.
What is the difference between an SEO tool stack audit and building a connected SEO pipeline?
Consolidation addresses the supply side — reducing redundant subscriptions and cutting tool overlap. Building a connected pipeline addresses the demand side — ensuring the tools that remain pass data forward to each other rather than terminating at export. Consolidation without pipeline-building produces a smaller stack that still requires humans to reconcile data between layers. The target is both: fewer redundant tools and explicit handoffs between the ones that remain.