GEO dashboards were built to answer one question: is your brand showing up in AI results? That question has an answer. It doesn't have a strategy attached to it.
Citation counts, AI Share of Voice, platform sentiment scores — these metrics tell you where you stand in AI-generated responses. What they don't tell you is what caused that standing, what's eroding it, or what a content team should do differently next week. The reporting layer most teams are running right now is an observation layer dressed up as a strategy tool. The gap between the two is where GEO programs stall.
This piece breaks down what's structurally wrong with how most GEO dashboards are built and what an execution-first reporting layer needs to contain instead. If you're earlier in the GEO process and want to understand how to structure content for AI citation, the GEO execution guide for performance marketers covers that ground first.
What Is a GEO Dashboard, and What Is It Usually Missing?
A GEO dashboard is a reporting interface that tracks how a brand appears in AI-generated search responses across platforms like ChatGPT, Perplexity, and Google AI Overviews. The gap in current versions isn't feature coverage — it's that visibility data doesn't connect to specific content or technical actions.
The standard GEO dashboard tracks some version of the following: brand mention frequency, AI Share of Voice against named competitors, citation rate by platform, and sentiment scoring on how AI describes the brand. These are valid inputs for understanding where you stand. On their own, they are not a system for improving it.
The fundamental problem is structural. GEO visibility tools were designed to surface what is happening in AI responses — and that's largely where they stop. The 'why it is happening' and 'what to change' layer is missing, which is why GEO dashboards fill up with data that doesn't translate into action.
The observation trap: a brand sees its AI Share of Voice at 14% versus a competitor's 31%. The dashboard confirms the gap. But it doesn't tell the team whether the gap is a content structure problem, an entity recognition problem, a freshness signal problem, or a citation authority problem. Without that diagnosis layer, the 14% figure sits on a slide and nothing changes.
Why GEO Metrics Don't Connect to Action
GEO metrics fail to drive action when they measure AI output without connecting it to the specific content inputs, structural signals, or distribution gaps that caused that output. Actionable GEO reporting requires tracking what the AI is retrieving, not just what it is saying.
Take brand mention rate — a common GEO metric. A rising mention rate looks credible until you realize that AI systems often cite the same handful of high-authority pages repeatedly, regardless of publishing volume. A healthy mention rate can mask the fact that only two pages are doing all the work, and everything else the brand has produced is invisible to AI retrieval systems.
Or take sentiment scoring. Knowing that ChatGPT describes your product positively is useful brand intelligence. It doesn't tell you which queries are triggering that positive framing, which competitor content is anchoring the contrast, or which pages are supplying the language the AI is borrowing. Tools like Otterly.ai and Profound offer monitoring depth on what AI is saying. Understanding what is causing it is a different problem — and a different layer of infrastructure.
The metrics that actually connect to action operate at a different level — content-level, prompt-level, and gap-level, rather than brand-level aggregates.
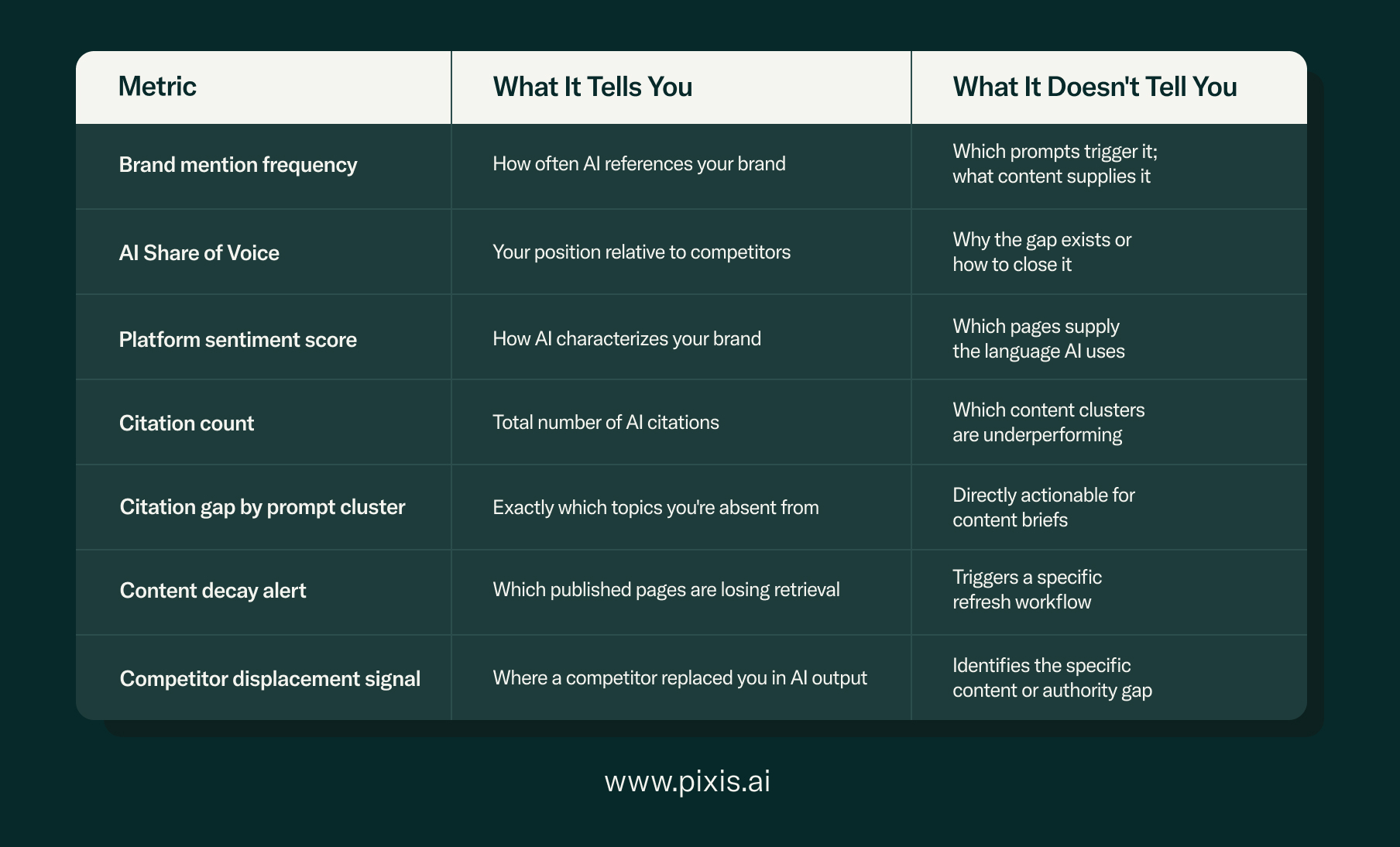
What Does an Execution-First GEO Dashboard Actually Need?
An execution-first GEO dashboard connects AI visibility data to specific content, technical, and distribution actions — not just where a brand is absent in AI results, but which pages to update, which gaps to brief, and which authority signals need attention.
Closing the gap between observation and execution requires three reporting layers that current GEO tools tend to handle in isolation, if at all.
1. Prompt-Level Citation Mapping
A dashboard that shows whether AI mentions your brand is answering the wrong question. The useful question is which specific query clusters trigger a mention and which ones don't. Citation gap analysis at the prompt cluster level is the GEO equivalent of keyword gap analysis in traditional SEO — it tells you what to create, not just how you're performing.
A brand selling B2B marketing software might appear consistently in AI answers to 'what is marketing automation' while being entirely absent from 'how to measure marketing ROI' — a higher-intent cluster where a competitor holds the majority of citations. Semrush's AI Overview tracking surfaces some of this at the keyword level, but prompt-cluster mapping for generative responses requires a layer that traditional SEO tools weren't built to provide. That absence is a content brief. The gap in the dashboard is only useful if it produces one.
2. Content Decay and Retrieval Freshness Signals
AI retrieval systems favor content that is authoritative, structurally coherent, and regularly updated. A page that earned citations six months ago can lose retrieval standing if it hasn't been refreshed, if its answer capsule structure has degraded, or if newer competitor content has displaced it in the model's training or index weighting.
An execution-first dashboard surfaces content decay alerts — specific URLs where retrieval performance is declining — so content teams have a prioritized refresh queue rather than a guessing game about what to touch next.
3. Competitive Displacement Tracking
The moment a competitor replaces your content as an AI citation source for a prompt you previously owned is a high-signal event. It isn't captured by Share of Voice trends, which smooth over displacement in aggregated scores. Tracking it at the prompt-query level turns passive monitoring into an early warning system — one that tells the team exactly where to respond and what kind of content or authority gap allowed the displacement to happen.
The read-only problem: GEO tools built around monitoring give you a read layer — they surface what AI is saying. What performance marketing teams actually need is a read/write layer — one that connects visibility gaps to specific execution steps. Monitoring without execution is expensive awareness with no path to impact.
How This Changes What You Should Build (or Buy)
For teams evaluating GEO tools — or trying to get more from the ones they already have — the evaluation criteria needs to shift from monitoring inputs to execution outputs. A dashboard that surfaces a visibility gap without pointing to a specific action is a reporting cost, not a strategic asset.
The questions worth asking of any GEO reporting layer are:
- Does it show me which specific content pages are earning or losing AI citations?
- Does it surface citation gaps at the prompt-cluster level, mapped to content opportunities?
- Does it alert me when competitor content displaces mine in AI results for a specific query?
- Does it connect visibility data to a content refresh or technical publishing action?
- Does it track performance over time at the page and prompt level, not just the brand level?
A tool that can't answer most of those questions is a monitoring tool. Monitoring tools establish baseline awareness, which has value at the start of a GEO program. They're the starting point — not the operating layer. Pixis Visibility is built as a read/write execution layer: it doesn't just surface where you're absent from AI results, it runs the content and technical actions that change that.
The Execution Gap Is the Real GEO Problem
The meaningful shift in GEO strategy right now isn't about which platforms to track or how frequently to pull reports. It's about whether the reporting infrastructure can produce a specific action. Teams that can answer 'are we visible in AI results?' but not 'what do we change to become more visible?' are running an incomplete program.
GEO dashboards built purely around observation will produce teams that know they have a gap but can't close it. That's a structure problem, not a data problem. More metrics won't fix it.
An execution-first approach changes the daily workflow. Weekly citation gap triage replaces monthly mention score reviews. Content refresh queues driven by decay alerts replace guesswork about what to update. Competitive displacement signals that map to specific content responses replace passive Share of Voice watching.
The dashboard worth building is the one that ends every session with a list of things to do, not a set of numbers to explain.
FAQ
What should a GEO dashboard track?
A GEO dashboard should track citation gaps by prompt cluster, content decay signals for pages losing AI retrieval, competitive displacement events when a competitor earns a citation your content previously held, and page-level citation performance over time. Brand-level aggregates like AI Share of Voice are useful for executive reporting but need to be supported by prompt-level and content-level data that connects visibility gaps to specific actions.
Why is my AI Share of Voice not improving despite publishing new content?
Publishing volume isn't the primary driver of AI retrieval. AI systems retrieve content based on structural coherence, answer capsule density, entity recognition, and freshness signals. New content that lacks answer-first structure, clear canonical prompts, or proper schema markup may not be indexed for retrieval even if it performs in traditional search. The issue is usually structural.
What is the difference between GEO monitoring and GEO execution?
GEO monitoring tells you what AI is currently saying about your brand — citation counts, mention frequency, sentiment. GEO execution connects that data to specific content, technical, or distribution actions that change what AI says. The monitoring layer is necessary for diagnosis. It becomes a problem when it's treated as the endpoint — when it substitutes for the workflow that's supposed to follow it.
How often should GEO performance be reviewed?
Citation gap analysis and content decay alerts are best reviewed weekly, since AI retrieval systems update continuously and competitive displacement can move quickly. Brand-level Share of Voice is better suited to monthly or quarterly review, as meaningful trend data takes time to accumulate. Teams that only review GEO performance at the brand level and on a monthly cadence tend to miss displacement events until they've compounded.